들어가며
마크다운과 Jekyll을 접한 지 그리 오래 되지 않았다. 가볍고 수동이며 완전히 customize할 수 있다는 점이 참 좋다.
그런데 새 포스트 쓸 때마다 아래와 같은 헤더를 넣어줘야 하는 건 조금 불편하다.
---
title: "[shell] 포스트 헤더 자동으로 만들기"
excerpt: "쉘 스크립트 자동화"
date: 2019-12-24 15:21:32 +0900
category: dev
tags:
- shell
- script
- automation
- post
---
이 블로그(minimal-mistakes 테마)에서 포스트 하나를 표시하기 위해서는 title, excerpt, date, category, tags를 써 주어야 한다. 그런데 저걸 언제 다 써! 결국 이전 포스트에서 헤더만 복사해서 재활용하게 된다.
복사와 붙여넣기는 원래 컴퓨터 전문이다. 사람이 할 일이 아닌 것이다. 그러므로 컴퓨터에게 시켜보자.
쉘 스크립트
왜 쉘 스크립트인가? 간단한 문제이기도 하고, 쉘 스크립트가 파일 입출력에 아주 능하기 때문이다.
유닉스 철학 중에 이런 것이 있다.
각 프로그램이 하나의 일을 잘 할 수 있게 만들 것. 새로운 일을 하려면, 새로운 기능들을 추가하기 위해 오래된 프로그램을 복잡하게 만들지 말고 새로 만들 것.
모든 프로그램 출력이 아직 잘 알려지지 않은 프로그램이라고 할지라도 다른 프로그램에 대한 입력이 될 수 있게 할 것. 무관한 정보로 출력을 채우지 말 것. 까다롭게 세로로 구분되거나 바이너리로 된 입력 형식은 피할 것. 대화식 입력을 고집하지 말 것.
오늘날의 거의 모든 쉘과 유틸리티는 저 철학을 잘 지켜서 만들어졌다. 덕분에 명령어 몇 개의 조합 만으로 많은 일을 처리할 수 있다.
$ echo "Hello world." | sed "s/o/O/g"
HellO wOrld.
“Hello world.” 스트링에서 소문자 ‘o’를 대문자 ‘O’로 바꾸는 예제
헤더 자동으로 만들기
헤더에서 바뀌는 부분은 (key:value) 쌍 중에 value 부분이다. 따라서 대부분은 변하기 않는다. 이를 템플릿 파일로 만들어 놓는다.
---
title: "__title__"
excerpt: "__excerpt__"
date: __date_time__ +0900
category: __category__
tags:
__tags__
---
template.md
그리고 이 파일을 읽어서 특정 키워드를 사용자의 입력으로 대치한 다음에 새 파일에 쓰면 된다.
쉘 선택
쉘은 Zsh을 사용한다. 왜냐 하면 Bash는 여러 줄 스트링을 지원하지 않기 때문이다.
bash-3.2$ echo "Hello\nworld"
Hello\nworld
Bash
zsh$ echo "Hello\nworld"
Hello
world
Zsh
스크립트 작성
스크립트의 흐름은 이렇게 된다:
- 파일명으로 사용할 스트링 입력 & 파일 중복 검사
- 타이틀 스트링 입력
- 발췌(excerpt) 스트링 입력
- 카테고리 스트링 입력
- 태그 스크링 입력
- 현재 날짜 기반으로 헤더 작성, 미리보기 출력
- 새 파일에 작성
아래는 완성본이다.
#!/bin/zsh
# Useful when creating new post.
# Usage: ./new
date=$(date +%Y-%m-%d)
time=$(date +%H:%M:%S)
date_time="$date $time"
echo "New post from $date_time.\n"
echo -n "Permalink name: "
read permalink
permalink=$(echo $permalink | sed "s/[ ]/-/g")
outfile="_posts/$date-$permalink.md"
# Check if any post with the same title exists.
if [ -f $outfile ]; then
echo "$outfile already exists."
exit 0
fi
echo -n "Title: "
read title
echo -n "Excerpt: "
read excerpt
echo -n "Category: "
read category
echo -n "Tags (space separated): "
read tags
# Replace every space-padded string to "- (captured);".
# And then cut last character ';'.
# We use ';' to represent newline character.
# This suck happens because the newline character is a bit tricky to handle.
tags=$(echo $tags | sed "s/[ ]*\([^ ]*\)[ ]*/ - \1;/g" | sed "s/.$//")
infile="_draft/template.md"
content=$(cat $infile |
sed "s/__title__/$title/" |
sed "s/__excerpt__/$excerpt/" |
sed "s/__date_time__/$date_time/" |
sed "s/__category__/$category/" |
sed "s/__tags__/$tags/" |
tr ';' '\n')
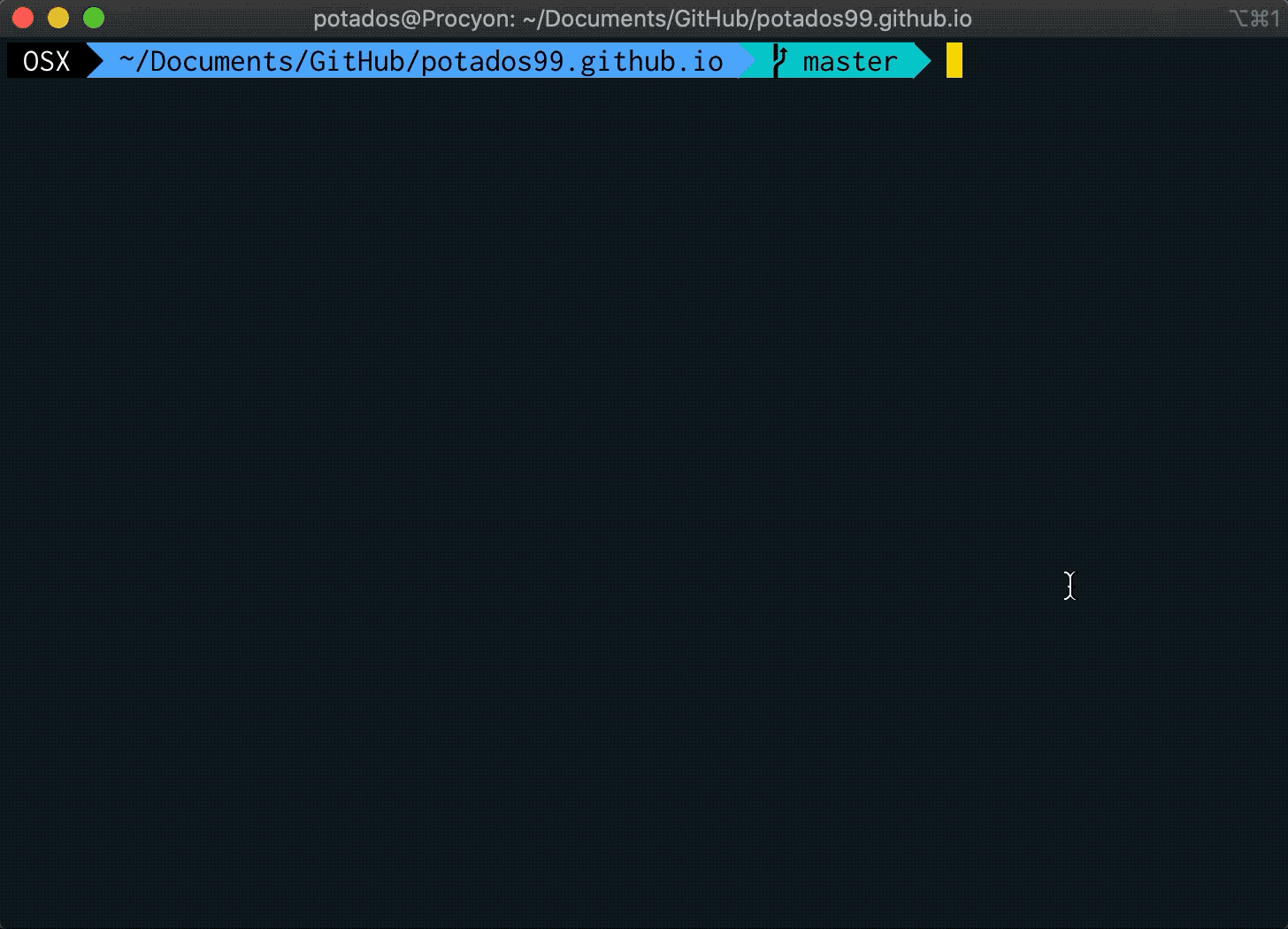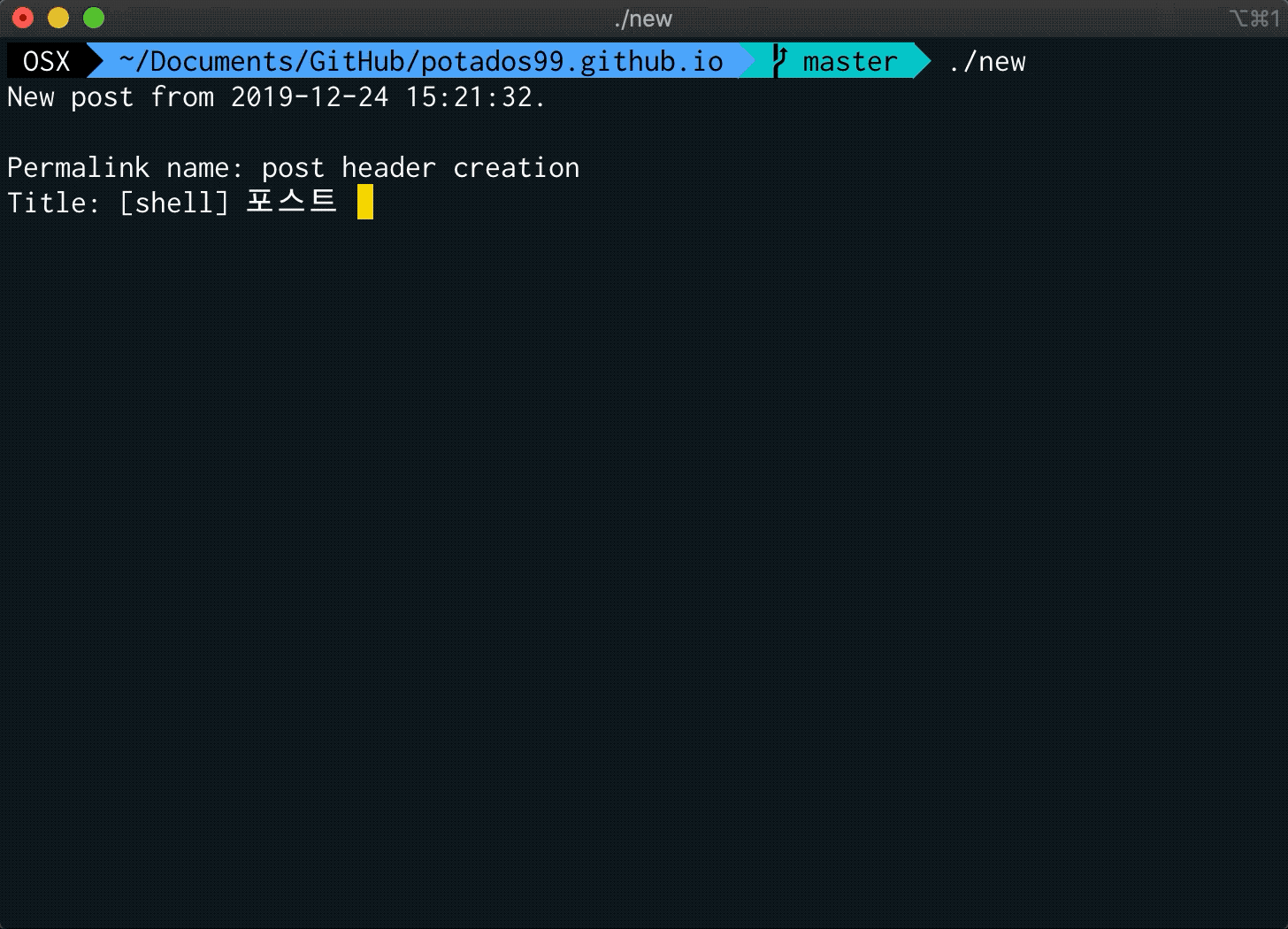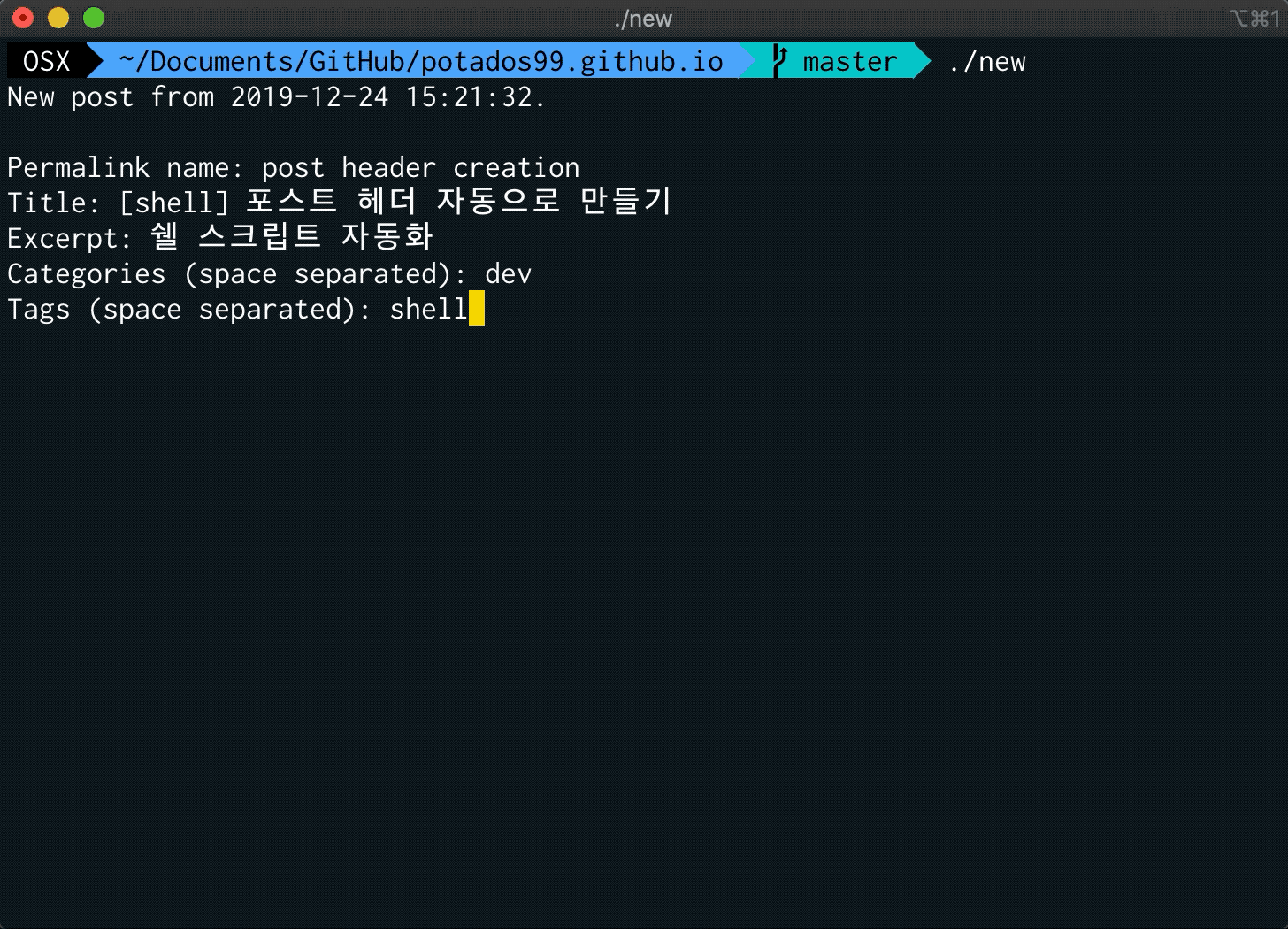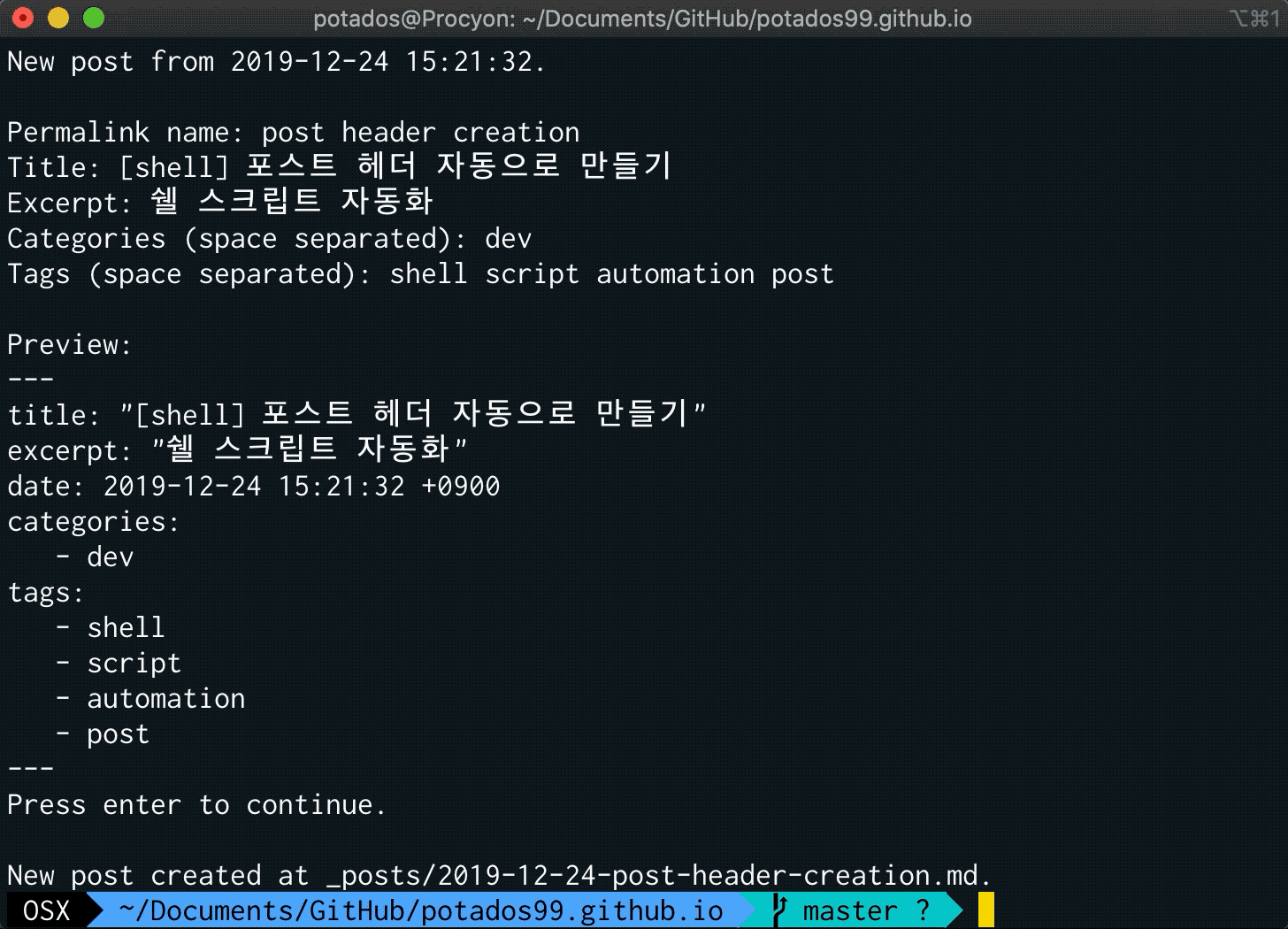
echo "\nPreview:"
echo $content
echo "Press enter to continue."
read
echo $content > $outfile
echo "New post created at $outfile."
삽질
아주 간단해 보이지만 위 완성본이 나오기까지 무수한 삽질을 겪었다 (내공 부족).
태그를 입력받을 때에 공백 문자로 구분하여 여러 개의 입력을 받고 싶었다. 그래서 “some tags hmm..” 이런 식으로 쓰면 아래처럼 정리되는 식이다.
tags:
- some
- tags
- hmm..
처음에는 스트링의 모든 공백을 \n문자로 대치한 다음 스트링 덩어리 왼쪽에 ` - 를, 오른쪽에 \n`을 붙일 생각이었다. 그런데 스트링 덩어리를 특정하려면 정규 표현식을 써야 한다.
어차피 정규 표현식을 사용할 것이면 공백 문자를 줄바꿈 문자로 대치할 필요 없이 바로 공백으로 구분되는 스트링을 그룹화하여 대치할 수 있다.
공백으로 구분되는 스트링은 다음과 같이 잡아낸다.
[ ]*\([^ ]*\)[ ]*
왼쪽에 공백 0개 이상, 본 스트링에 공백 0개, 오른쪽에 공백 0개 이상을 만족하는 스트링을 찾아내는 정규표현식
이를 이용해 sed로 대치하면 된다.
category=$(echo $category)
tags=$(echo $tags | sed "s/[ ]*\([^ ]*\)[ ]*/ - \1;/g" | sed "s/.$//")
줄바꿈 대신 ;을 사용했는데, sed가 \n를 무시하기 때문이다 (원래 single line editor이다). 파일에 쓰기 직전에 tr을 사용해 모든 ; 문자를 \n 문자로 대치한다.
sed "s/.$//"는 마지막 ;를 떼어내기 위해 사용했다.
마치며
쉘 스크립트는 잘 몰라서 쓸 때마다 찾아보게 된다. 쉘마다 문법도 다르고 동작도 달라서 많이 헷갈린다.
이 스크립트는 Zsh에서는 잘 돌아가지만 Bash에서는 이상하게 동작한다. 언젠가 호환성을 생각해서 다시 짜야 할 것 같다.
아무튼 덕분에 글 쓰기 편해졌다. 역시 도구를 잘 써야 해.
프로그래밍 작업을 가볍게 하기 위해, 심지어 우회하는 방법으로 도구를 만들고 바로 버릴지라도 어설픈 도움 보다는 도구 사용을 선호할 것.
“유닉스 철학 - Kenneth Lane Thompson”
댓글